NBA
NBAPythonNBA
5Team Per Ganme StatsOpponent Per Game StatsMiscellaneous Stats2015-2016 NBA Schedule and Results2015-162016-2017 NBA Schedule and Results2016-2015
NBA
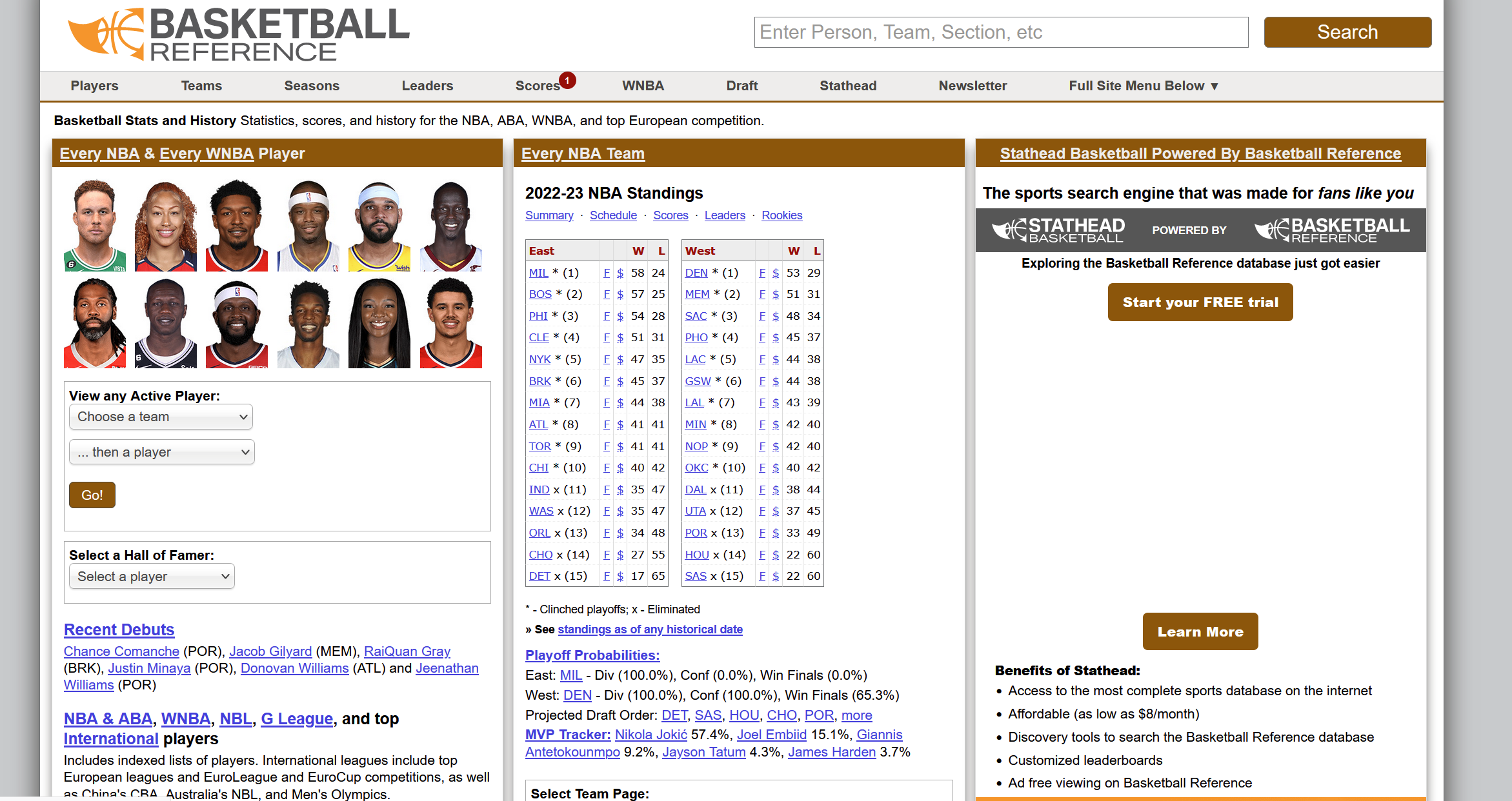
Team Per Ganme Stats
Opponent Per Game Stats Team Per Game Stats
Miscellaneous StatsAdvanced Stats
Team Per Game StatsOpponent Per Game StatsMiscellaneous StatsNBAAdvanced Stats
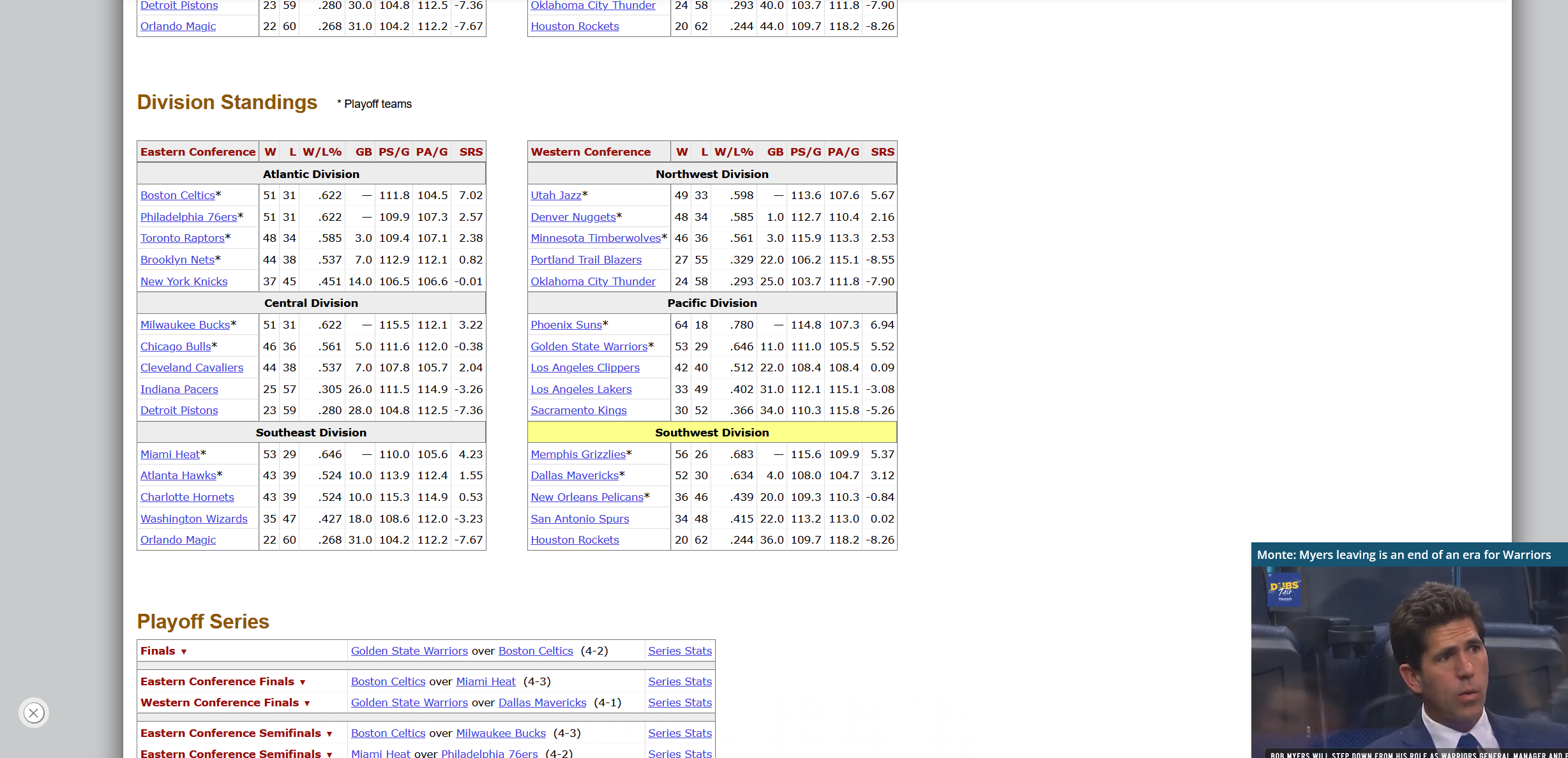
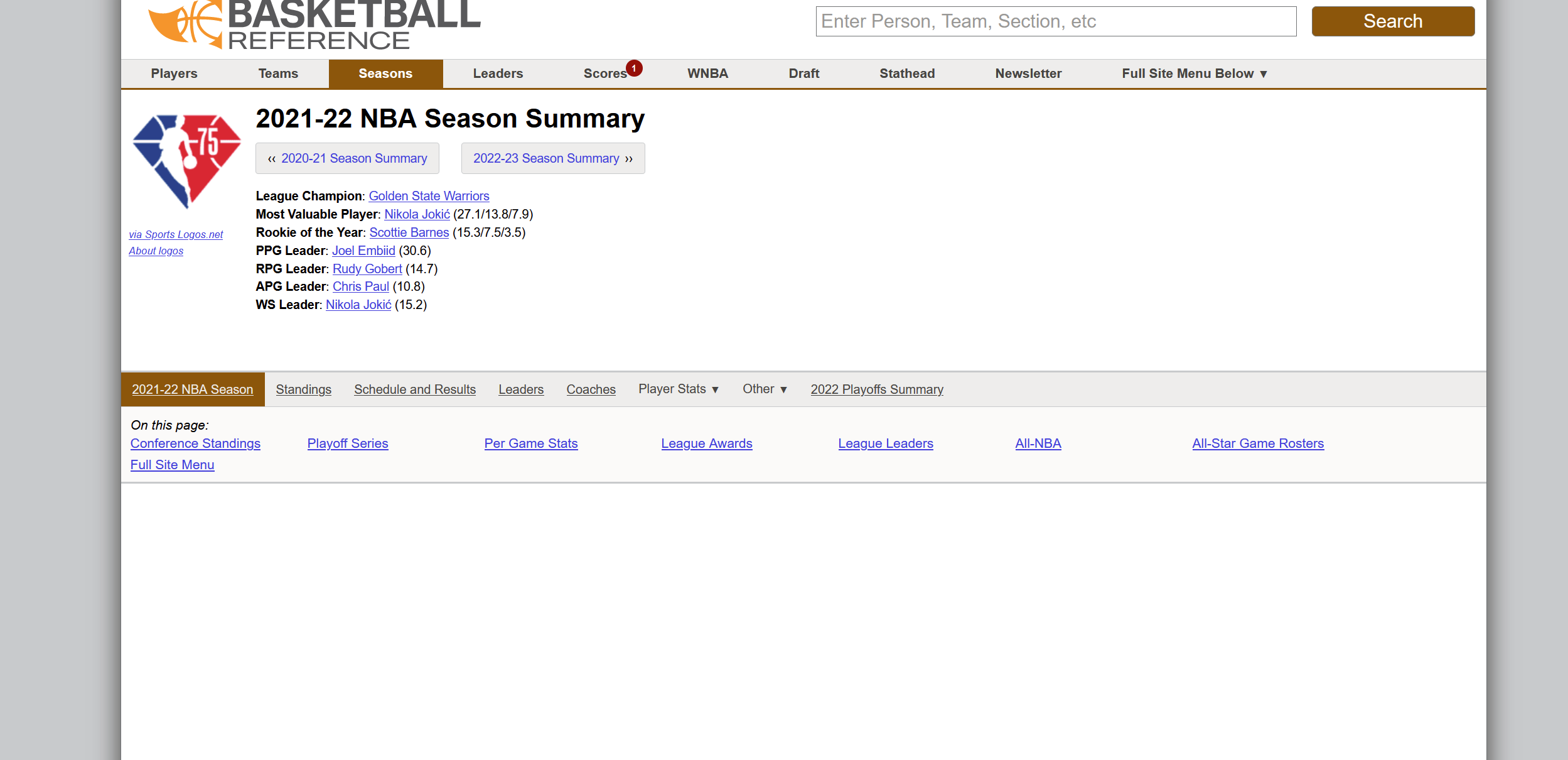
2020-2021 NBA Schedule and Results2020-2021 NBA 2020-2021 NBA Schedule and Results 2020-2021 NBA
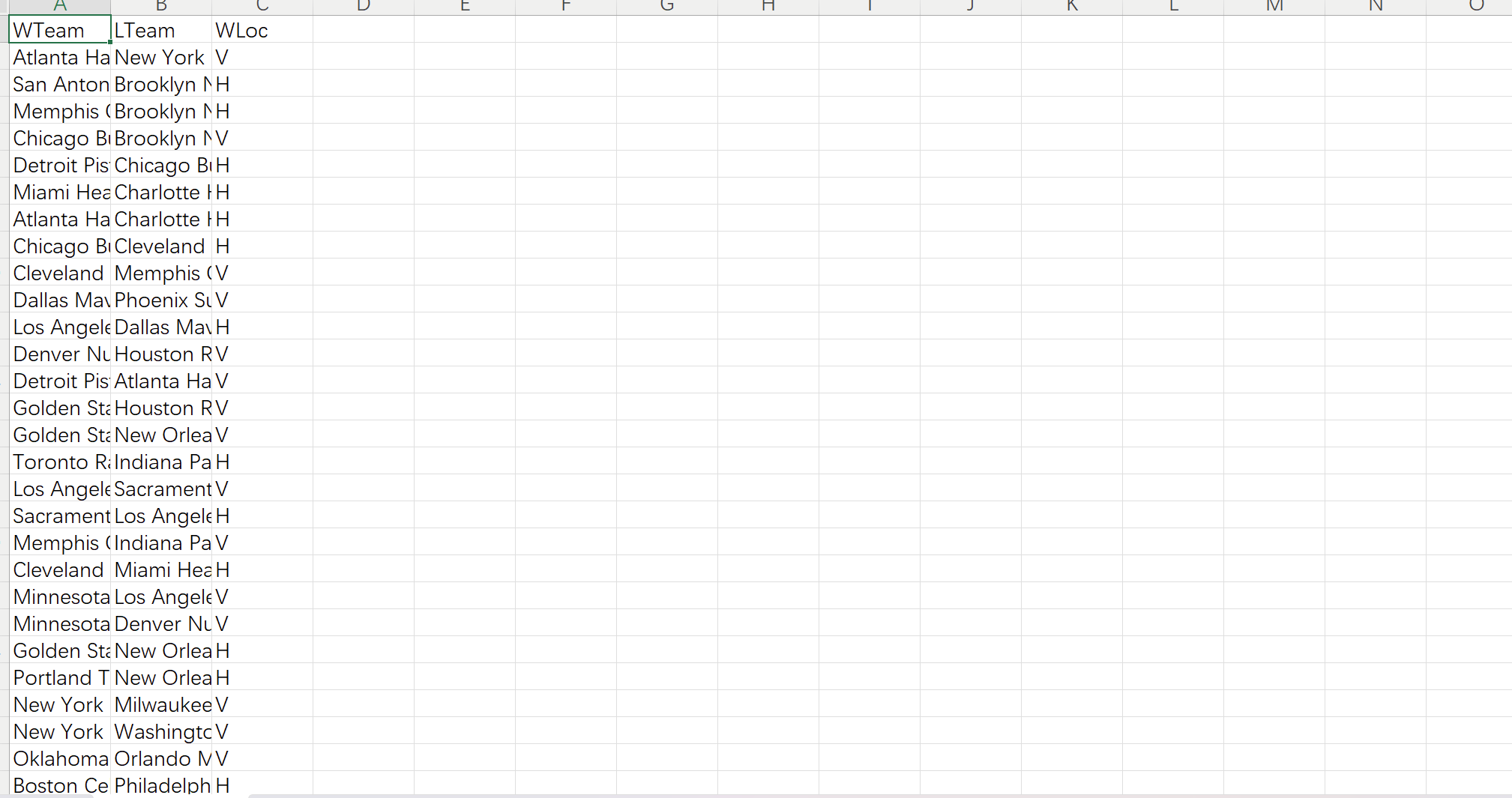
Vteam: Hteam:
Elo
Team Per Game StatsOpponent Per Game Stats Miscellaneous Stats TO M
TO Elo
import requests import re import csv class NBASpider: def __init__(self): self.url = self.headers = User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 def send(self): response = requests.get(self.url) response.encoding = utf-8 return response.text html def parse(self, html): team_heads, team_datas = self.get_team_info(html) opponent_heads, opponent_datas = self.get_opponent_info(html) return team_heads, team_datas, opponent_heads, opponent_datas def get_team_info(self, html): htmlteam :param html :return: team_heads team_datas 1. table team_table = re.search(table.*?id=per_game-team.*?(.*?)/table, html, re.S).group(1) 2. table team_head = re.search(thead(.*?)/thead, team_table, re.S).group(1) team_heads = re.findall(th.*?(.*?)/th, team_head, re.S) 3. table team_datas = self.get_datas(team_table) return team_heads, team_datas opponent def get_opponent_info(self, html): htmlopponent :param html 1. table opponent_table = re.search(table.*?id=per_game-opponent.*?(.*?)/table, html, re.S).group(1) 2. table opponent_head = re.search(thead(.*?)/thead, opponent_table, re.S).group(1) opponent_heads = re.findall(th.*?(.*?)/th, opponent_head, re.S) 3. table opponent_datas = self.get_datas(opponent_table) return opponent_heads, opponent_datas body def get_datas(self, table_html): tboday :param table_html table :return: tboday = re.search(tbody(.*?)/tbody, table_html, re.S).group(1) contents = re.findall(tr.*?(.*?)/tr, tboday, re.S) for oc in contents: rk = re.findall(th.*?(.*?)/th, oc) datas = re.findall(td.*?(.*?)/td, oc, re.S) datas[0] = re.search(a.*?(.*?)/a, datas[0]).group(1) datas = rk + datas yield datas yield datas csv def save_csv(self, title, heads, rows): f = open(title + .csv, mode=w, encoding=utf-8, newline=) csv_writer = csv.DictWriter(f, fieldnames=heads) csv_writer.writeheader() for row in rows: dict = for i, v in enumerate(heads): dict[v] = row[i] csv_writer.writerow(dict) def crawl(self): 1. res = self.send() 2. team_heads, team_datas, opponent_heads, opponent_datas = self.parse(res) 3. csv self.save_csv(team, team_heads, team_datas) self.save_csv(opponent, opponent_heads, opponent_datas) if __name__ == __main__: spider = NBASpider() spider.crawl()

import requests import re import csv class NBASpider: def __init__(self): self.url = self.schedule_url = self.headers = User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36 def send(self, url): response = requests.get(url, headers = self.headers) response.encoding = utf-8 return response.text html def parse(self, html): team_heads, team_datas = self.get_team_info(html) opponent_heads, opponent_datas = self.get_opponent_info(html) return team_heads, team_datas, opponent_heads, opponent_datas def get_team_info(self, html): htmlteam :param html :return: team_heads team_datas 1. table team_table = re.search(table.*?id=per_game-team.*?(.*?)/table, html, re.S).group(1) 2. table team_head = re.search(thead(.*?)/thead, team_table, re.S).group(1) team_heads = re.findall(th.*?(.*?)/th, team_head, re.S) 3. table team_datas = self.get_datas(team_table) return team_heads, team_datas opponent def get_opponent_info(self, html): htmlopponent :param html :return: 1. table opponent_table = re.search(table.*?id=per_game-opponent.*?(.*?)/table, html, re.S).group(1) 2. table opponent_head = re.search(thead(.*?)/thead, opponent_table, re.S).group(1) opponent_heads = re.findall(th.*?(.*?)/th, opponent_head, re.S) 3. table opponent_datas = self.get_datas(opponent_table) return opponent_heads, opponent_datas body def get_datas(self, table_html): tboday :param table_html table :return: tboday = re.search(tbody(.*?)/tbody, table_html, re.S).group(1) contents = re.findall(tr.*?(.*?)/tr, tboday, re.S) for oc in contents: rk = re.findall(th.*?(.*?)/th, oc) datas = re.findall(td.*?(.*?)/td, oc, re.S) datas[0] = re.search(a.*?(.*?)/a, datas[0]).group(1) datas = rk + datas yield datas yield datas def get_schedule_datas(self, table_html): tboday :param table_html table :return: tboday = re.search(tbody(.*?)/tbody, table_html, re.S).group(1) contents = re.findall(tr.*?(.*?)/tr, tboday, re.S) for oc in contents: rk = re.findall(th.*?a.*?(.*?)/a/th, oc) datas = re.findall(td.*?(.*?)/td, oc, re.S) if datas and len(datas) 0: datas[1] = re.search(a.*?(.*?)/a, datas[1]).group(1) datas[3] = re.search(a.*?(.*?)/a, datas[3]).group(1) datas[5] = re.search(a.*?(.*?)/a, datas[5]).group(1) datas = rk + datas yield datas yield datas def parse_schedule_info(self, html): htmlteam :param html :return: team_heads team_datas 1. table table = re.search(table.*?id=schedule data-cols-to-freeze=,1(.*?)/table, html, re.S).group(1) table = table + /tbody 2. table head = re.search(thead(.*?)/thead, table, re.S).group(1) heads = re.findall(th.*?(.*?)/th, head, re.S) 3. table datas = self.get_schedule_datas(table) return heads, datas csv def save_csv(self, title, heads, rows): f = open(title + .csv, mode=w, encoding=utf-8, newline=) csv_writer = csv.DictWriter(f, fieldnames=heads) csv_writer.writeheader() for row in rows: dict = if heads and len(heads) 0: for i, v in enumerate(heads): dict[v] = row[i] if len(row) i else csv_writer.writerow(dict) def crawl_team_opponent(self): 1. res = self.send(self.url) 2. team_heads, team_datas, opponent_heads, opponent_datas = self.parse(res) 3. csv self.save_csv(team, team_heads, team_datas) self.save_csv(opponent, opponent_heads, opponent_datas) def crawl_schedule(self): months = [october, november, december, january, february, march, april, may, june] for month in months: html = self.send(self.schedule_url.format(month)) print(html) heads, datas = self.parse_schedule_info(html) 3. csv self.save_csv(schedule_+month, heads, datas) def crawl(self): self.crawl_schedule() if __name__ == __main__: spider = NBASpider() spider.crawl()
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181
send(self, url): response = requests.get(url, headers=self.headers, timeout=30
parse(self, html): team_heads, team_datas =
self.get_team_info(html) opponent_heads, opponent_datas =
team_heads, team_datas, opponent_heads, opponent_datas
htmlteam :param html :return: team_heads team_datas
1. table team_table = re.search(
table.*?id=per_game-team.*?(.*?)/table
2. table team_head = re.search(
htmlopponent :param html :return:
1. table opponent_table = re.search(
table.*?id=per_game-opponent.*?(.*?)/table
2. table opponent_head = re.search(
3. table opponent_datas =
tboday :param table_html table :return:
get_schedule_datas(self, table_html):
tboday :param table_html table :return:
th.*?a.*?(.*?)/a/th
get_advanced_team_datas(self, table): trs = table.xpath(
html :param html :return: heads datas
1. table table = re.search(
table.*?id=schedule data-cols-to-freeze=,1(.*?)/table
2. table head = re.search(
xpathhtml :param html :return: heads datas
1. table table = selector.xpath(
self.get_advanced_team_datas(table)
save_csv(self, title, heads, rows): f = open(title +
csv.writer(f) csv_writer.writerow(heads)
rows: csv_writer.writerow(row) f.close()
2. team_heads, team_datas, opponent_heads, opponent_datas =
, team_heads, team_datas) self.save_csv(
self.send(self.schedule_url.format(month))
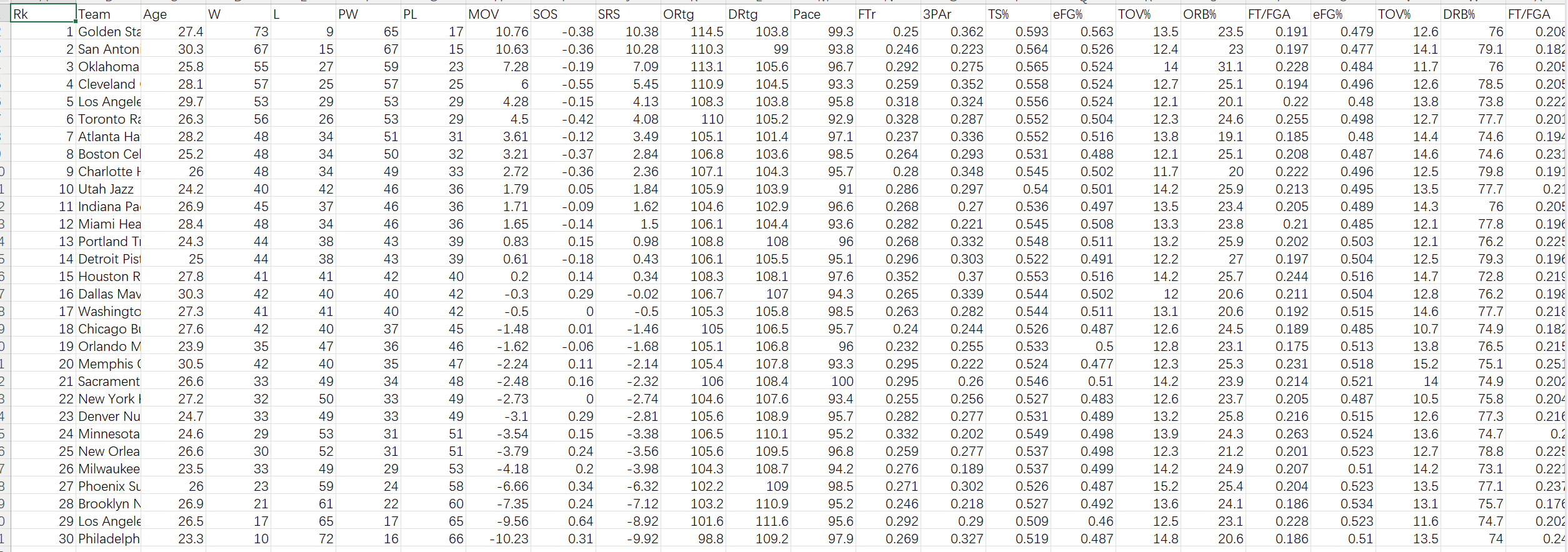
team
pruneM = M_stat.drop([
indexteam mergeMO = rge(pruneM, pruneO, how =
) newstat = pd.merge(mergeMO, pruneT, how =
elo E1 = 1/(1 + math.pow(10,(R2 – R1)/400
)) E2 = 1/(1 + math.pow(10,(R1 – R2)/400
GenerateTrainData(stat, trainresult):
[[team1team2]…[]…] X =
trainresult.iterrows(): winteam = rows[
stat.loc[winteam].iteritems(): fea_win.append(value)
stat.loc[loseteam].iteritems(): fea_lose.append(value)
team elo win_new_score, lose_new_score =
CalcElo(winteam, loseteam) team_elos[winteam] =
win_new_score team_elos[loseteam] =
nan_to_num(x)0xnaninf
info.loc[team1].iteritems(): fea1.append(value)
info.loc[team2].iteritems(): fea2.append(value)
nan_to_num1array2.X
M_stat = pd.read_csv(folder +
) team_result = pd.read_csv(folder +
PruneData(M_stat, O_stat, T_stat) X,y =
GenerateTrainData(teamstat, team_result)
linear_model.LogisticRegression() limodel.fit(X,y)
print(cross_val_score(model, X, y, cv=10, scoring=
GeneratePredictData(pre_data, teamstat) pre_y =
limodel.predict_proba(pre_X) predictlist =
pre_data.iterrows(): reslt = [rows[
corresponding probability of winning
corresponding probability of winning
parselimport
CondaHTTPError:HTTP 000 CONNECTION FAILED for url
httphttpshttpchannels